このメモは、次世代RAGフレームワーク「LightRAG」と、その中核をなす高速ベクトル検索技術「HNSW」の仕組みについて、個人的にまとめたものです。
1. LightRAGの全体像とアーキテクチャ
1.1. 従来のRAGが抱える課題とLightRAGの解決策
従来のRAG(検索拡張生成)は、情報を単なるテキストの塊(チャンク)として扱うため、以下のような課題がありました。
- 情報の断片化: 複数の文書にまたがる複雑な質問に対し、文脈が途切れた断片的な回答しか生成できない。
- 関係性の欠如: 「A社がB社を買収した」と「B社の創設者は田中氏」という2つの情報から、「A社が田中氏を迎え入れた」という関係性を導き出すことが困難。
LightRAGは、この課題をナレッジグラフを用いて解決します。テキストからエンティティ(ノード)と関係性(エッジ)を抽出し、「意味の地図」として構造化することで、深い文脈理解と一貫性のある回答生成を可能にします。
1.2. LightRAGのアーキテクチャ:2つの頭脳の連携
LightRAGは、役割の異なる2つの主要なデータストア(頭脳)を連携させて動作します。以下の図は、その全体構造を示しています。
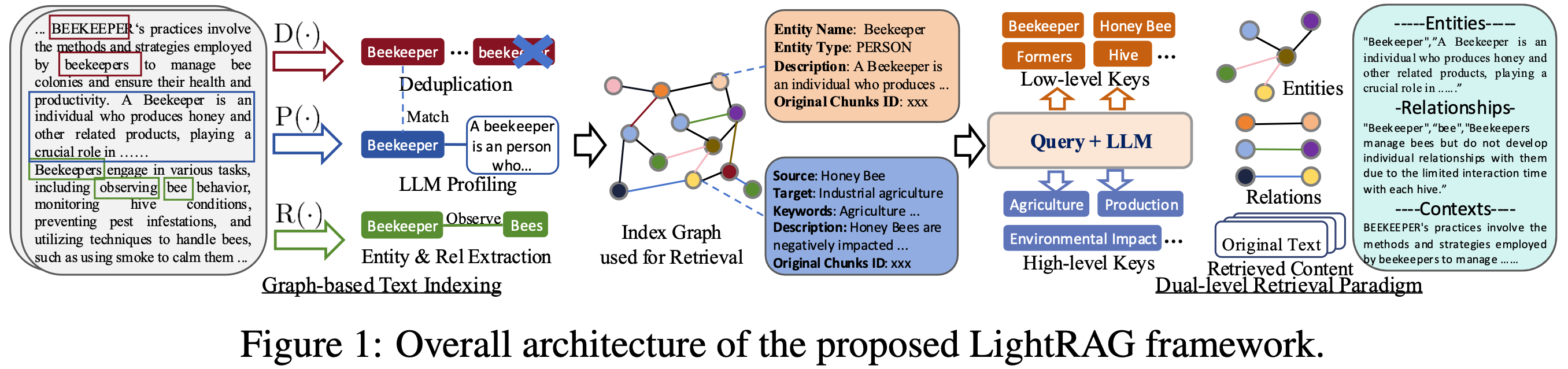
図1: LightRAGの構造
- ナレッジグラフ・ストア (Knowledge Graph Store)
役割: 「意味を理解する脳」として機能します。ノード(例: A社)、エッジ(例: 買収した)、そしてそれらの構造的なつながりを保持します。データ間の論理的な関係性を管理する役割を担います。
構造: このグラフ自体は階層化されておらず、単一でフラットなネットワーク構造です。 - ベクトルデータベース (Vector Database)
役割: 「超高速な反射神経」として機能します。ナレッジグラフ内の各要素(ノードやエッジの説明文など)をベクトル化して保存し、高速な類似検索を実現します。
内蔵エンジン: このデータベースの内部には、検索を高速化するための索引(インデックス)技術としてHNSWが組み込まれています。
1.3. LightRAGの動作フロー①:ナレッジグラフの構築
LightRAGは、以下のステップで非構造化テキストからナレッジグラフを構築します。
- 抽出 (Extraction): LLMを使い、テキストからエンティティ(人物、組織など)と、それらの間の関係性を抽出します。
- プロファイリング (Profiling): 抽出した各ノードとエッジに対し、LLMが検索用のキーワードや要約文を付与します。この情報がベクトル化され、ベクトルデータベースに登録されます。
- 重複排除 (Deduplication): 新しく抽出されたエンティティが既存のものと同一かを判定します。同一であれば、新しいノードは作らず、既存のノードに情報を統合します。この判定には、エンティティの正規化された名前などから生成されるハッシュ値がIDとして用いられると考えられます。
1.4. LightRAGの動作フロー②:デュアルレベル検索
ユーザーからの質問に答える際、LightRAGは独自のデュアルレベル検索パラダイムを用います。
- 低レベル検索 (Low-Level Retrieval): 「A社のCEOは誰?」のような、具体的なエンティティに関する質問に対応します。質問から「A社」「CEO」といったキーワードを抽出し、特定のノードをターゲットに検索を行います。
- 高レベル検索 (High-Level Retrieval): 「近年のAI業界の動向は?」のような、広範で抽象的なテーマに関する質問に対応します。「AI業界」「動向」といったキーワードから、複数のノードやエッジ(関係性)を横断的に検索し、全体的な文脈を捉えます。
この2つの検索は、ベクトルデータベースのメタデータ(例: type='node', type='edge')を利用して効率的に(多くの場合、非同期で)実行され、得られた結果をナレッジグラフ上で統合し、最終的な回答を生成します。
2. 中核技術HNSW:高速検索の心臓部
HNSW (Hierarchical Navigable Small World) は、膨大なベクトルデータの中から、目的のベクトルに最も近いものを高速に見つけ出すためのアルゴリズムです。
2.1. 階層化の仕組み:ランダム性こそが鍵
HNSWの最大の特徴は、その巧妙な階層化の仕組みです。以下の図は、その階層構造を模式的に示しています。

図2: HNSWの階層構造
- 階層決定は完全にランダム:
新しいデータ点が追加されるたびに、その点がどの階層まで所属するかは、そのデータの内容や重要度とは一切関係なく、サイコロを振るようにランダムな確率で決まります。階層が上がるほど、その階層に所属する確率は指数関数的に低くなります。 - 階層構造の役割:
このランダム性により、自然と効率的な階層構造が生まれます。- 上位階層: メンバーが非常に少ないため、データ空間全体を横断する「高速道路」のような長距離リンクが形成されます。
- 下位階層 (0階): 全てのメンバーが所属するため、「一般道」のような短距離リンクが密集したネットワークが形成されます。
2.2. 探索の仕組みと新規データ追加
HNSWは、この階層構造を活かして、以下の手順で探索を行います。
- 最上位から開始: 探索は、最もまばらな最上位レイヤーの「エントリーポイント」から始まります。
- 貪欲な探索 (Greedy Traversal): 現在いるノードから、リンクで繋がっている隣人の中で、最もクエリ(探したいデータ)に近い隣人へと移動します。この計算には、テキストベクトルの場合、コサイン類似度が一般的に用いられます。
- 下の階層へ: そのレイヤーで「これ以上近づけない」という局所的な最適解に達したら、その地点を新しい開始点として、一つ下の、より密なレイヤーに降りて探索を続けます。
- 繰り返し: このプロセスを最下層(0階)まで繰り返すことで、最終的な検索結果を得ます。
また、HNSWは増分更新が可能で、新しいデータが追加された際も、この探索アルゴリズムを使って自身の最適な場所を見つけ出し、ネットワークにスムーズに統合されます。
3. 個人的に気になった疑問と回答
ここでは、私がHNSWに関して抱いた疑問とその回答をまとめます。
Q: HNSWの上位レイヤーが「コアな単語」や「マイナーな単語」だけで構成された場合、探索はうまくいきますか?
A: はい、問題ありません。階層への所属はランダムであり、単語の重要度には依存しません。上位レイヤーの役割は、データ空間全体にバランス良く「ショートカット網(高速道路)」を構築することです。そのため、構成要素が何であれ、ナビゲーション機能は頑健に働きます。
Q: 探索中に極所解に陥ることはありますか?
A: 極めて陥りにくい設計になっています。その理由は、①階層決定のランダム性、②トップダウンの探索戦略、そして次に説明する③賢い隣人選びのヒューリスティックという3つのメカニズムが連携して機能するためです。
Q: 「多様な方向にある隣人を選ぶヒューリスティック」とは?
A: これは、リンクの「数」ではなく「質」と「配置」を工夫するルールです。単純に最も近い隣人とだけリンクを結ぶと、すべてのリンクが同じデータクラスター内に集中し、探索が孤立する危険があります。このヒューリスティックは、たとえ少し距離が遠くても、自分から見て多様な方向にある隣人とバランス良くリンクを結ぶことを促します。これにより、クラスター間に意図的に「橋」が架けられ、探索が袋小路に入るのを防ぎます。
Q: 各ノードのIDはハッシュ値ですか?
A: 論文に直接の記載はありません。しかし、LightRAGの重要機能である「重複排除(Deduplication)」を実現するためには、IDが「決定的(同じエンティティからは必ず同じIDが生成される)」である必要があります。この要件を最も満たすのがハッシュ値です。エンティティの正規化された名前などからハッシュ値を計算し、それを一意なIDとして使用していると考えるのが最も合理的です。
4. 参考文献
- LightRAG: Guo, Z., Xia, L., Yu, Y., Ao, T., & Huang, C. (2024). LightRAG: Simple and Fast Retrieval-Augmented Generation. arXiv preprint arXiv:2410.05779.
- HNSW: Malkov, Y. A., & Yashunin, D. A. (2018). Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs. IEEE transactions on pattern analysis and machine intelligence, 42(4), 824-836.